Lucene BKD树-动态磁盘优化BSP树
当我对遇到的问题找一个解决方案的时候,我遇到了BKD树这个难题。从来没有听过吗?这种情况可能不只是你自己。从google上搜索”bkd tree”,通常会把你引导到original research paper和Lucene中用来解决一些空间搜索的patch 网页,然后就没有其他的了。实际上,在写这篇文章的时候,google的第2篇文章推过来的是wikipedia上与这个比较相似名称的 K-D-B Tree。BKD树太冷门了,google都以为你是想找其他的。
BKD树作为一个这么伟大的发明,google这样对待它,这是相当不幸的。
BKD树是用来搜索多维数据的一种树。多维数据可以是物理空间中的一些点,也可以是一个很大调色板上的一些点。BKD树相当善于做其他数的工作。相比和BKD同类型的树,BKD树通常比K-D-B树以及更简单的 R-Trees更快,更节省空间。
本篇文章不是一个对BKD树简单的罗列或者详细描述的wikipedia。我尝试用大白话来讲解BKD树是怎么运作的,有哪些特性。
BSP Trees
BKD树是BSP(Binary Space Partitioning)树家族的一员。BSP树在计算科学中应用广泛。BSP树不止处理标准的Map和Set操作,还能把一些其他的操作更加的高效。比如范围查询(空间内所有点)和最近邻查询(离某个点最近的点)。
这些树在概念上和二叉查找树很像。我们把空间分割成块,而不用查找整个空间。BSP使用一个超平面来切分空间。比如,我们有一个遍布点的 100 x 100 x 100立方体,要查找(10,20,30)这个点。我们可以把这个立方体切分为2个部分:1个部分X>50,另1部分<50。因为我们是要查询X=10的点,所以我们只需要去查找第2部分就可以了。BSP树不断递归的分隔空间。下面是对这个的一个图形化展示:
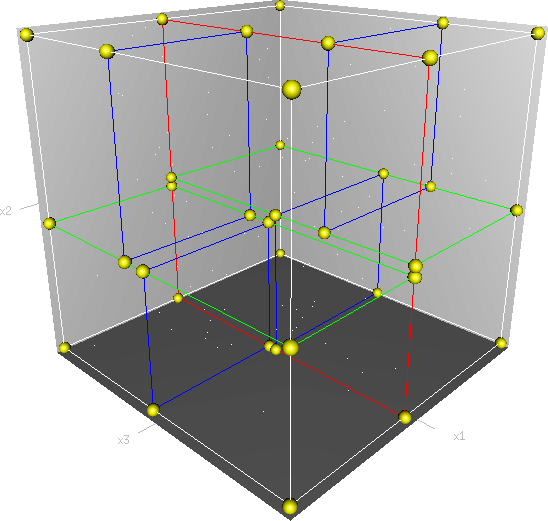
“3dtree”. Licensed under GPL via Commons — https://commons.wikimedia.org/wiki/File:3dtree.png#/media/File:3dtree.png
k-d Trees
k-d Trees 是一种最普通的BSP树. K-D树以及下面提到的变种树,它们的key可以是任意维的数据。而其他的一些BSP树,像Quadtrees 或者 Octrees 只能用来表示2D和3D空间。K-D树实现起来,很像是一个二叉查找树(BST)。主要的区别是,K-D树的key对比在不同的层使用的是不同的维度值。下面是一个2维树的样例:
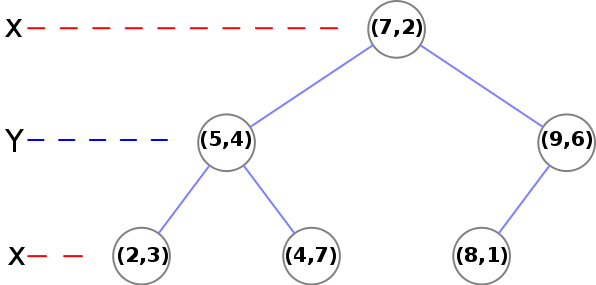
“Tree 0001” by MYguel — Own work. Licensed under Public Domain via Commons — https://commons.wikimedia.org/wiki/File:Tree_0001.svg#/media/File:Tree_0001.svg
和二叉查找树一样,如果K-D树是平衡的,那么他的时间复杂度就是 O(log n)。当然这个前提是树是平衡的。假如一个树先添加一个点(1,1)然后加入点(0,0),那么2个点都会在树的左侧,这就导致了不平衡。更为难办的是,在K-D树上我们不能使用类似树旋转等标准的树平衡技术。我们唯一能做的就是完全重建子树才能让树平衡,就像 Scapegoat Tree 提到的。
标准的K-D树在动态更新的场景下表现的并不好,只有在数据是静态的情况下才表现优异。游戏里的资产列表就是一个场景。
K-D-B Trees
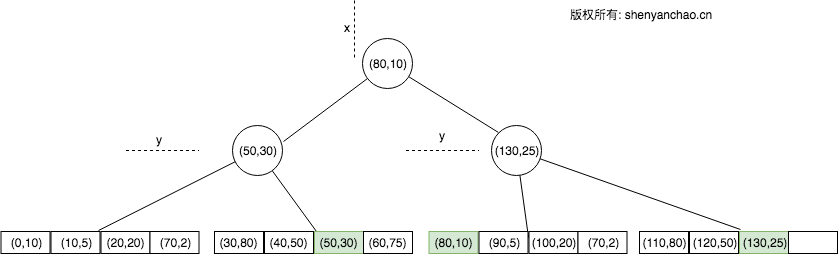
这次要讲的是K-D-B树。这个树是K-D树和 B+ Tree树的结合体。像标准的K-D树一样,一个内部的node把空间切分成几个不同的区域。和K-D树不一样的是,内部node不是包含的点。空间里的区域由2个点来定义,一个点是各个维度最小位置,而另一个定义了各个维度最大的位置???。下面的图展示了一个包含3个区域,每个叶子包含3个点的K-D-B树。需要注意的是这2个值可以不一样。通常情况下,区域的个数是小于叶子点的个数的。每个节点的区域是按照一个坐标轴来排序的,不像K-D树是在不同level分坐标轴排序的。
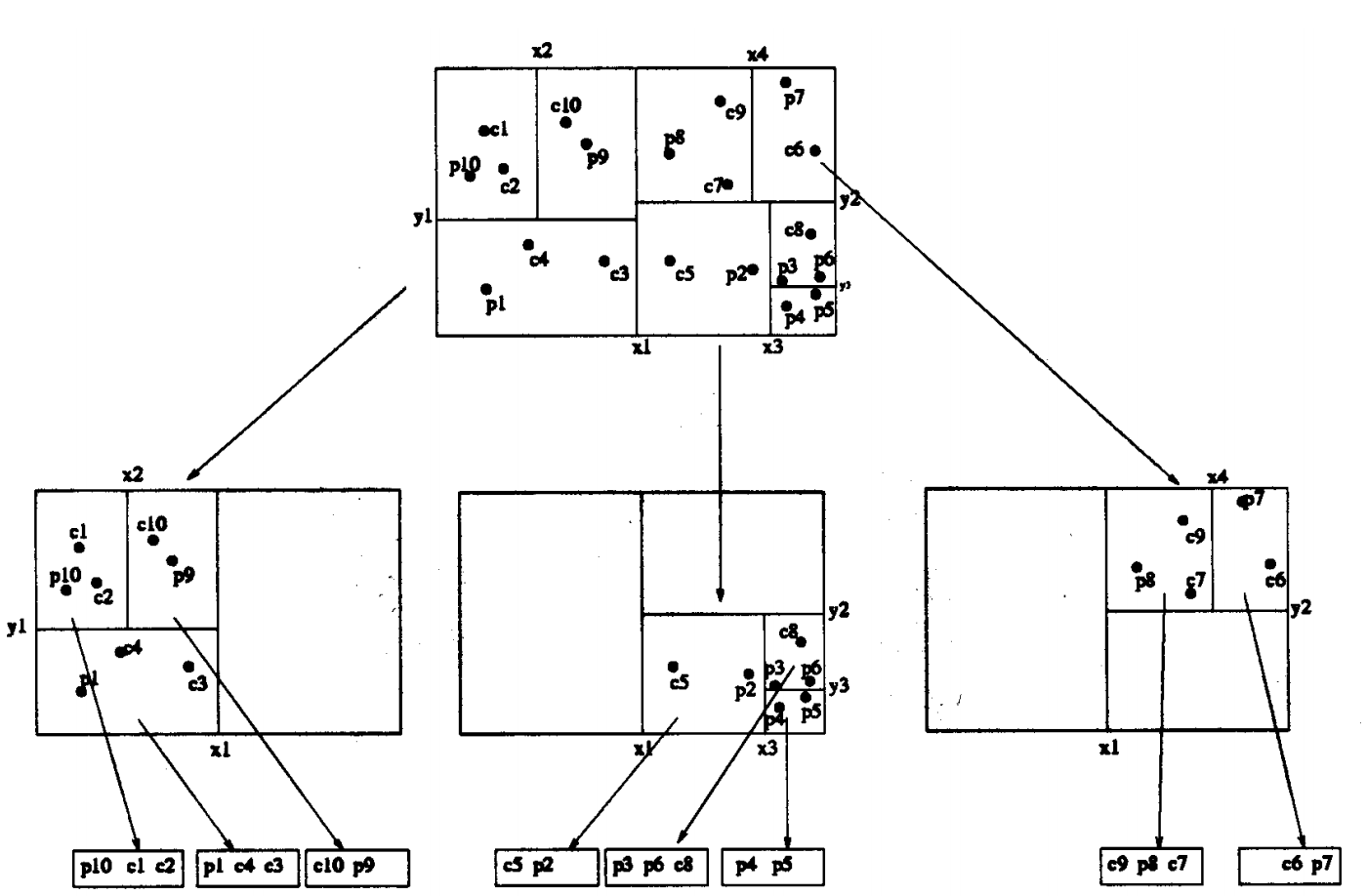
因为BKD树被组织成B树一样,所以在磁盘上可以工作的很好。随着每个node有更多的扇出,node会更大,相对来说树也就更浅。通常来说,磁盘延迟较大,但是吞吐很高。也就是说读取大块的数据和读取小块的数据耗费的时间成本是差不多的,大块数据是一个优势。更浅的深度也意味着更少的非本地读。通常我们把node的大小设置的至少和page(4KB)大小一样, 或者是成倍的关系。正因为如此,一个node可以包含数百的点。
和其他B树的变种一样,也要求是平衡的。当然这是通过插入操作来保证的。插入一个元素到叶子上,如果叶子没有满,直接插入。如果叶子满了,就进行切分。不像你想的那样,来增加树的深度,而是增加一个新的兄弟节点来解决。如果一个区域node满了,那就有一点复杂了。
???假如我们需要对左下方区域进行垂直切分。因为现在已经有4个区域了,所以它的父区域也要进行切分。这意味着要对空间的整个左侧区域进行切分。这是K-D-B树的一大缺陷。切分一个区域通常需要切分它的子区域。修改会导致树大量的修改,当需要往磁盘写的时候,就更慢了。
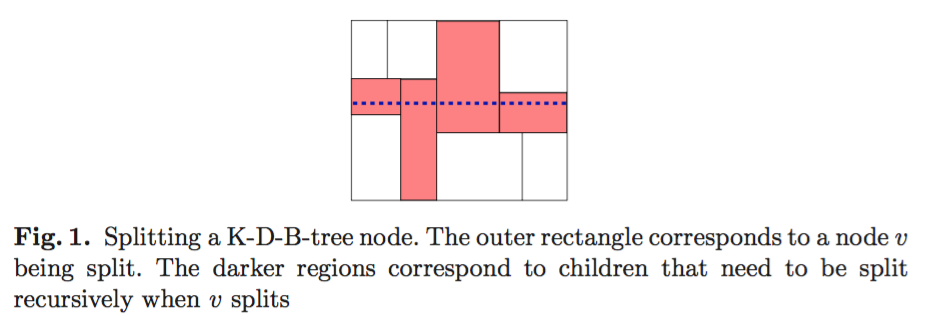
Bkd-Tree: A Dynamic Scalable kd-Tree
另外一个劣势是内存利用率。由于没有对一个node有多满做限制,这会导致大量的空间浪费。这不止影响磁盘数据的大小,也对性能有较大的影响,因为有更少的pages可以放在 page cache.
hB Trees
值得一提的是,有另一个K-D-B树存在。hB树或Holey Brick树试图解决这个问题,不再切分整个区域,而是切分城有空洞的不规则的区域。这超出了本片的范围,如果有兴趣的话可以去读一下,它的文档比BKD树更好。
Bkd Trees
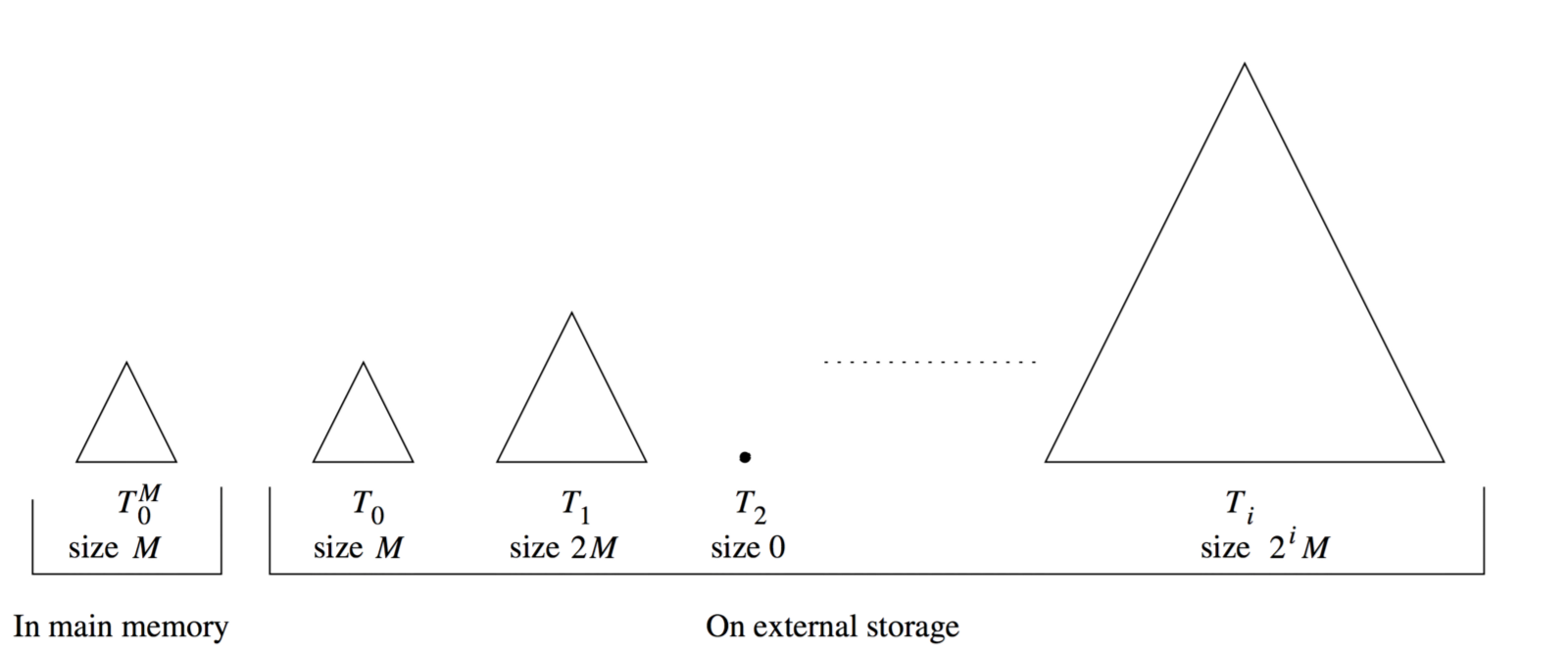
BKD树可以解决空间和插入效率问题。BKD树由多个可修改的KD树构成,并且有统一的插入方法。下面这个图是这些树的其中之一:
BKD树是二叉树和B+树的组合。比较特殊的是,内部node必须是一个完全二叉树,而叶子node存储的则和K-D-B树一模一样。
有一些特点减轻了二叉树在磁盘上的使用难度。因为这是一个完全二叉树,node不需要存储到它们子node的指针,直接使用乘法就可以了。假如一个node的位置在i,那这个node的左node在位置2i,右node在2i+1。既然叶子节点包含所有点数据,node不需要包含它们自己的任何数据。更小的node,意味着更多的数据可以存储在缓存内。大量的点数据存储在节点内,也降低了树的深度。
一个更大更有意思的部分是,BKD树的内部树是不会被修改的。BKD使用了一个更聪明的方法来添加新的点数据。
首先,有一个大小为M的Buffer。在论文里,他是被保存在内存的。这个Buffer, 可能仅仅是一个数组或者性能更好的一些数据结构,毕竟是有查询需求的。论文并没有给出这个Buffer的最优大小,但是直觉上来说,至少应该和被修改的K-D树node一样大。
Bkd-Tree: A Dynamic Scalable kd-Tree
如果BKD树由N个数据,那么它有 log2(N/M)个可修改的K-D树。每一个树都是前一个树的2倍。数据首先被插入到内存里的Buffer里,一旦Buffer满了,先定位到第1个为空的树。这个Buffer的数据,以及空树之前所有节点的数据一起生成一个满的平衡树。在论文里,有一个对这个算法的详细描述。
起初来看这可能是很耗时的,但从长远来看却是很高效的。???粗略的来看,我不认为write操作之后,直接fsync刷新数据到磁盘能有多高效,论文里并没有标明。
Real Performance真实性能
Bkd-Tree: A Dynamic Scalable kd-Tree
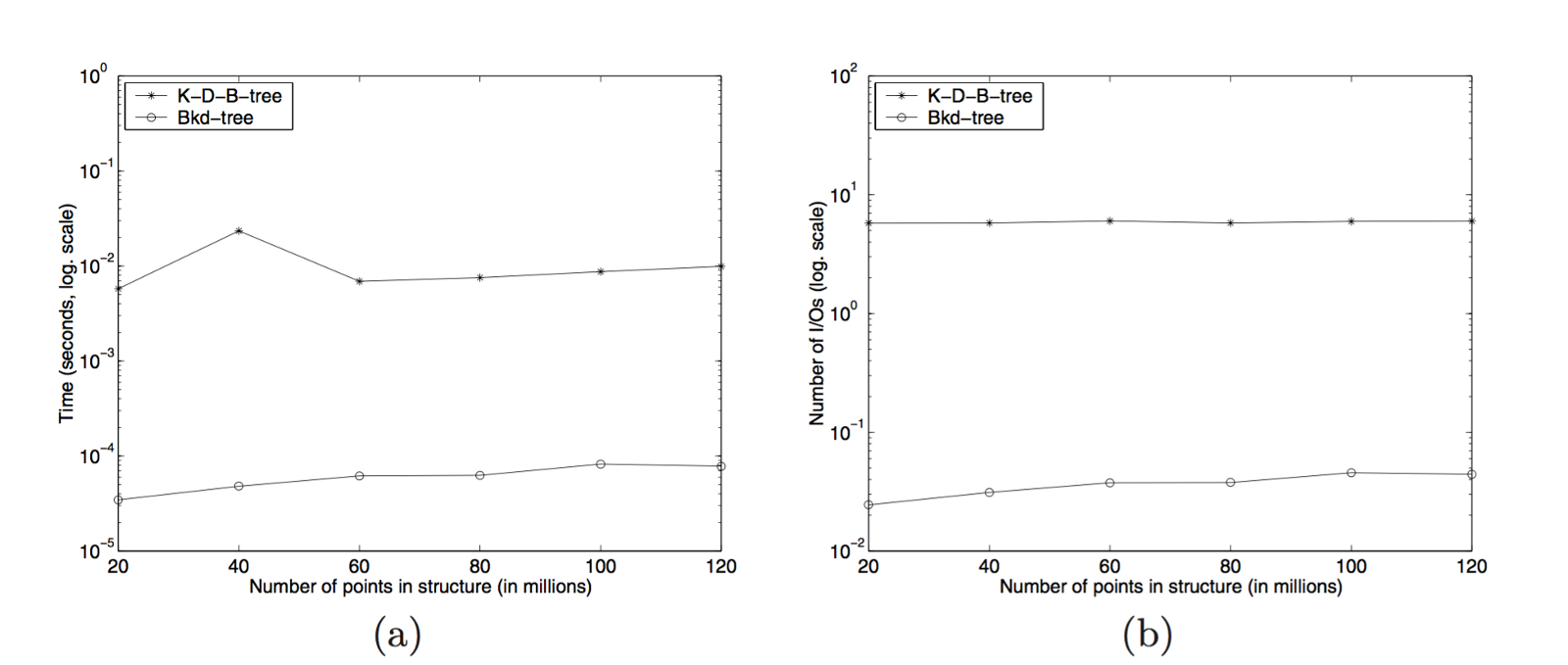
对于插入操作,BKD树比K-D-B树有2个量级的快。插入120M点数据的时间是50ms。这个数据是令人印象深刻的,但是当你知道使用的硬件设备是什么样的时候,你会更加的震惊。
我们使用了Dell PowerEdge 2400工作站,Pentium III/500MHz处理器,操作系统是FreeBSD 4.3。36GB的SCSI硬盘(IBM Ultrastar 36LZX)用来存储相关文件:输入的点数据、数据结构、临时文件。这个机器本身有128MB的内存,但是我们通过限制,是的TPIE可以用到的只有64MB。
简单来说,这是真的快,不是开玩笑的。大部分的插入操作都直接进入了Buffer,直接使用的是RAM,而不是CPU缓存。更令人感兴趣的是树的构建和写入。
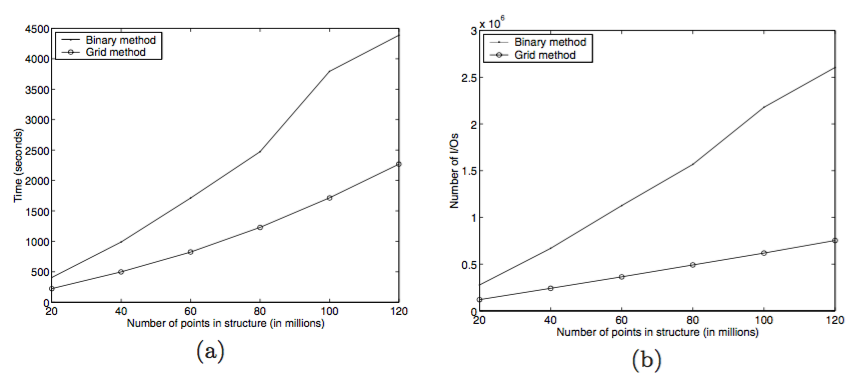
构建和写入是很耗时、开销很大的。尽管可以通过顺序写磁盘来优化,但是大量数据的移动是不可避免的。实际上,上面的例子,肯定有一个树至少存在60M的节点。创建这个有多耗时呢?
Bkd-Tree: A Dynamic Scalable kd-Tree
根据提供的测试数据,1个插入操作可以花费超过10分钟来创建和写入。这看起来令人大跌眼球,但是你需要记住一些事情。
第一:这都是在极其陈旧的硬件上实现的。现代的CPU更快,SSD则可以彻底改变这种情况。
第二:这种情况很罕见。越是耗时的操作,出现的概率越低。就想上面看到的,真实的吞吐量是特别优异的。
第三:数据可以边插入边读取。插入操作不修改任何已经存在的树结构,在构建一个新的树之前。由于IO和缓存争用,读操作很可能会慢一些,但不会被阻塞。
如果我不得不猜测,插入的尖峰特性在现代硬件上不会成为问题,除非您需要实时插入的能力。一旦我实现了这个结构来确认这一点,我计划用我自己的基准测试来更新本文。
查询树很容易,但效率略低。必须对每个修改过的K-D树以及Buffer执行查询。由于这些树都很小,这在同等条件下会比K-D-B树慢,但不会超过一个数量级。下面是一个非常大范围的查询(占整个空间的1%,或者大约是一个400M乘400M的范围)。
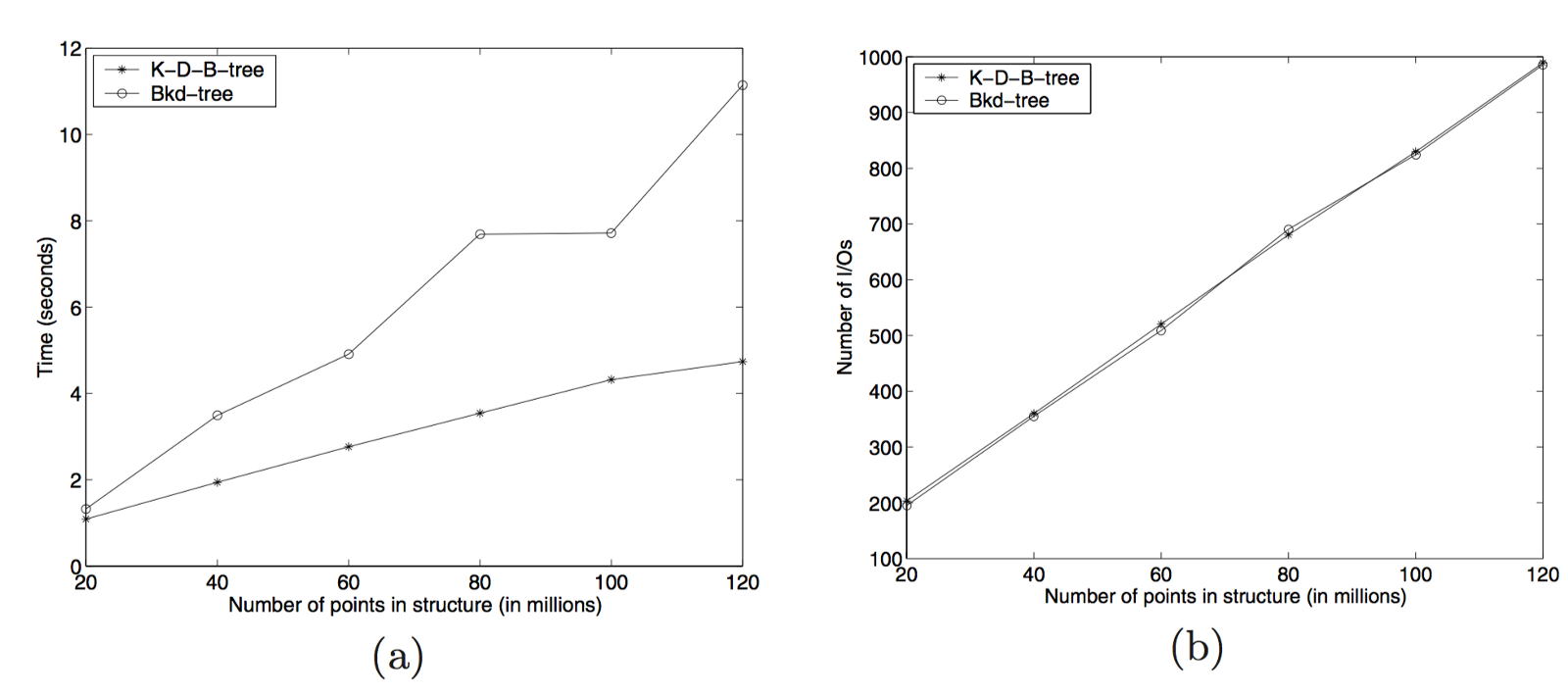
Bkd-Tree: A Dynamic Scalable kd-Tree
简单的查询会比这个更惊人的快,这在论文里没有体现。如果范围查询性能是你的首要关注点,BKD树有可能并不是最优的数据结果。
最后,我们来看下空间利用率的问题。我们期望这可能是近乎完美。这个图表用一个统一的随机和真实的数据集来说明空间利用率。
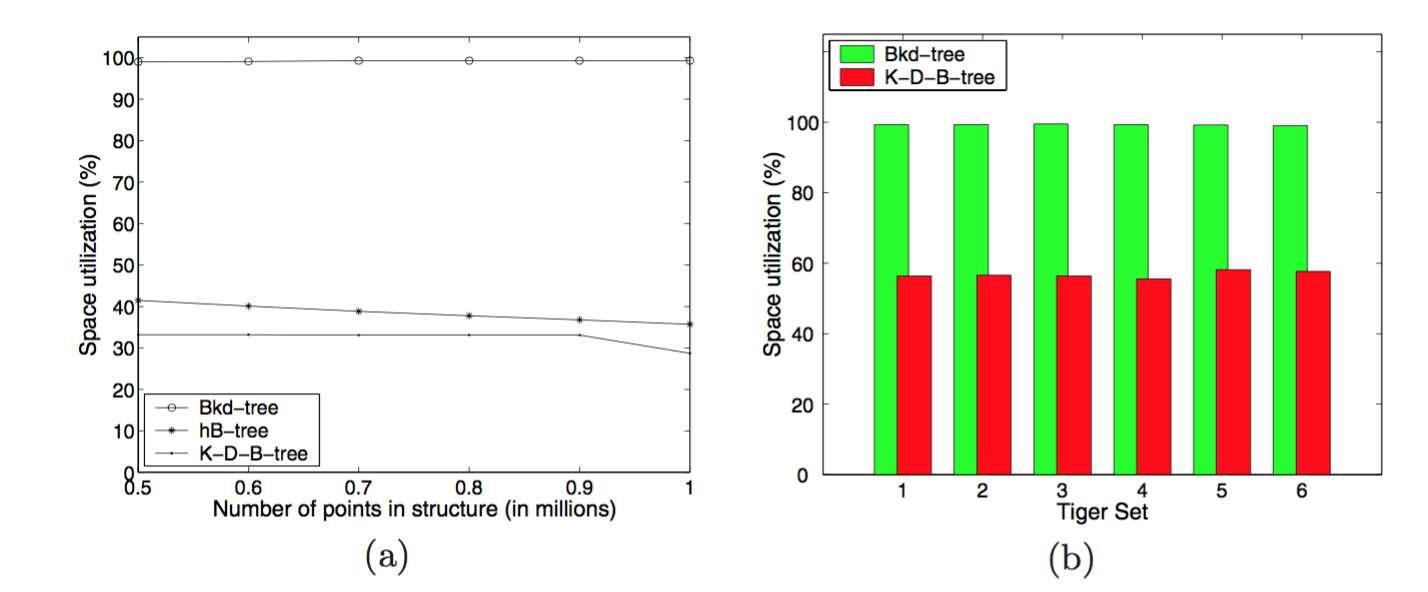
Bkd-Tree: A Dynamic Scalable kd-Tree
一个需要关注的点是,论文没有给出如何压缩已删除数据点的方法。随着更多的点从叶子node删除,空间利用率将随之降低。然而,我们可以自己来实现。
综上所述,BKD树是一种独特的数据结构,理论上具有很高的摊余写性能和空间利用率。当然它有许多潜在的有趣的应用场景。在下一篇文章中,我将描述此数据结构的具体实现,并进行一个现代硬件级的性能比较。