如何在Solr中更好的处理同义词
当使用Solr来构建搜索引擎的时候,你可能经常会遇到这样的场景:你有一个同义词列表,并且你想用户查询也能够命中到同义词。听起来很简单不是吗?为什么搜索“dog”的时候,不能命中包含“hound(猎犬)”或者“pooch(狗)”的文档呢?甚至包含“Rover(流浪者)”和“canis familiaris(犬)”?

叫Rover或者其他名字,可能只是为了让小狗听起来很可爱。
事实证明,Solr的同义词扩展没有你想象的那么简单。但是我们有很多好的方法来搬石头砸自己的脚。
The SynonymFilterFactory
Solr提供了一个听起来很酷的SynonymFilterFactory,它可以接收一个逗号分割的同义词文本。你甚至可以选择同义词是相互扩展还是特定方向的替换。
举例来说,你可以让“dog”,“hound”和“pooch”都扩展为“dog|hound|pooch”,或者你可以指定“dog”映射到“hound”,反过来却不可以,或者你可以把所有的词都转化为”dog“,Solr处理这部分是非常灵活的并且做的很棒。
当你考虑是把SynonymFilterFactory放在查询分析器还是索引分析器时,这个问题就变得很复杂啦。
Index-time vs. query-time
下图总结了查询时(query-time)和索引时(index-time)同义词扩展的基本差异。当然我们是为了解决solr中使用的问题,但是这2种方法适用于任何信息检索系统。
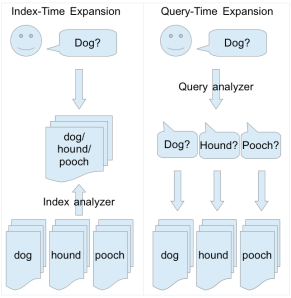
你的直观选择可能是将SynonymFilterFactory放在查询分析器内。理论上,这样做有以下优点:
- 索引大小不会变化
- 同义词可以随时更换,不用更新索引
- 同义词实时生效,不需要重新索引
然而,按Solr Docs所说,这是一个Very Bad Thing to Do(™),显然的你应该把SynonymFilterFactory放在索引分析器里,而不是简单的依靠你的直觉来判断。文档里说,查询时的同义词扩展有以下的缺点:
- 多字同义词并不能识别为短语查询
- 罕见同义词的IDF会被加权,导致不可想象的搜索结果
- 多字同义词不会匹配查询
这有点复杂,因此也值得我们一一解决这些问题。
多字同义词并不能识别为短语查询
在Health On the Net,我们的搜索引擎使用MeSH来做查询扩展,MeSH是一个为健康领域提供优质同义词的医疗本体。例如”breast cancer“的同义词:
1 | breast neoplasm |
因此在正常情况下,如果SynonymFilterFactory配置了expand="true",查询”breast cancer“就变成了:
1 | +((breast breast breast breast breast cancer cancer) (cancer neoplasm neoplasms tumor tumors) breast breast) |
这将命中包含”breast neoplasms“,”cancer of the breast”等等的文档。
然而,这也意味着,如果你正在做一个短语查询(比如”breast cancer“),如果想生效,你的文档必须字面上匹配类似”breast cancer breast breast“这样的字符。
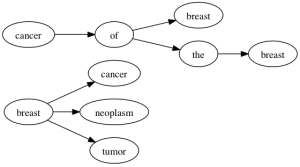
啊?这里到底发生了什么?事实证明SynonymFilterFactory并没有按你所想来扩展多字同义词。直觉上,可能认为它表现为一个有限自动机,Solr构建出的结果可能类似这样(忽略复数):
但是,它真正构建的是下面这样的:
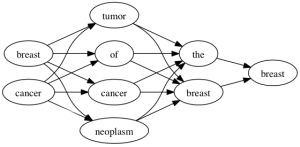
简直是一碗意大利面。
你可怜的文档必须依序包含所有的4个部分。让人惊讶。
同样,DisMax和EDisMax查询分析器的mm(最小匹配)参数,并不能像你所想的那样工作。在上面的例子中,设置mm=100%将需要所有4个部分都匹配。
+((breast breast breast breast breast cancer cancer) (cancer neoplasm neoplasms tumor tumors) breast breast)~4
罕见同义词的IDF会被加权
即使你没有多字同义词,Solr Docs也提到了第二个避免查询时扩展的原因:不正常的IDF加权。考虑我们的”dog”,”hound”,”pooch”例子,查询3个里面的任意一个都会被扩展为:
+(dog hound pooch)
由于“hound”和”pooch“是比较少见的字,因此无论查询什么,包含这些字的文档会在查询结果中排名特别高。这对可怜的用户来说,简直是一个浩劫,为什么搜索”dog“的时候,会有那么多包含”hound“和”pooch“的怪异文档排名那么高。
索引时扩展通过给”dog”,”hound”,”pooch”赋予相同的IDF值,而不管原始文档是什么。
多字同义词不会匹配查询
最后,也是最严重的是,如果你对用户查询做任意类型的分词,SynonymFilterFactory并不会匹配多字同义词。这是因为分词器会将用户输入分开,然后才交给SynonymFilterFactory来转换。
比如,查询“cancer of the breast”会被StandardTokenizationFactory分词为[“cancer”,”of”,”the”,”breast],并且只有独立的词才会传给SynonymFilterFactory。因此,在这种情况下,如果分词后的单个词,比如‘cancer“和”breast“都没有同义词的情况下,同义词扩展就压根不会发生。
其他问题
最初,我按照Solr的建议,使用索引时扩展,但是我发现索引时同义词扩展有它自己的问题。显然,除了有索引爆炸的问题,我还发现一个关于高亮的有趣的bug。
当我搜索”breast cancer“的时候,我发现高亮器会很神奇的把”breast cancer X Y“给高亮了,其中”X“和”Y“是文档中任何跟在”breast cancer“后面的2个字符。例如,它可能会高亮”breast cancer frauds are“或者”breast cancer is to“。

看完这个solr bug,这和前面提到的Solr多字同义词扩展是一个原因。
使用查询时扩展,你的查询被转换为像意大利面般的图已经足够的怪异了。但是在索引时扩展,假如你的文档包含”breast cancer treatment options“,会变成什么样子呢。
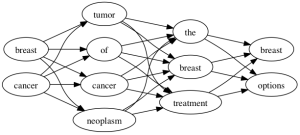
这就是Lucene认为的你文档的样子。同义词扩展给你带来了比你要求更多的东西,类似”Dada-esque“的结果!”Breast tumor the options“确实是这样的。
从根本上来说,Lucene认为一个查询”cancer of the breast“(4个Token)和你原始文档里的”breast cancer treatment options“(4个Token)是一样的。这是因为Tokens只是一个叠加另一个上面而已,丢失任何信息的部分都可以由它后面的部门来替代。
查询时扩展不会引起这个问题,因为Solr只扩展了查询,而不是文档。因此Lucene仍然认为查询的”cancer of the breast“只会匹配文档里的”breast cancer“。
总结
所有这些古怪的问题,让我得出这样的结论:Solr内建的同义词扩展机制是及其糟糕的。我必须找出一个更好的方法来让Solr按我想的来运行。
总之,无论是索引时扩展还是查询时扩展使用标准的SynonymFilterFactory都是不可行的,因为它们都有各自不同的问题。
Index-time
- 索引爆炸
- 同义词不能立即生效,所有文档需重新索引
- 同义词不能立即删除
- 多字同义词导致多余的文字被高亮
Query-time
- 短语查询不支持
- 罕见同义词被认为加权了
- 多字同义词不匹配查询
我开始假设理想的同义词扩展系统应该是基于查询时的,由于基于索引的扩展有那么多固有的缺点。同时,我也意识到在Solr实现同义词扩展之前,有一个更加根本的问题需要解决。
回到”dog“/“hound”/“pooch”的例子,对待3个词对等的是不明智的。在特定的查询中,”dog“可能并不与”hound“和”pooch“是一样的,比如 (e.g. “The Hound of the Baskervilles,” “The Itchy & Scratchy & Poochy Show”). 一视同仁感觉是错误的。
同样的,即使使用官方推荐的索引时扩展,IDF权重也被抛弃了。每个包含”dog“的文章现在也都包含”pooch“,这意味着我们将永久的丢失关于”pooch“的真实IDF值。
在一个理想的系统里,搜索”dog“,返回的结果应该包含所有存在”hound“和”pooch“的文档,但是应该将所有包含真实查询的文档排的更靠前面,包含”dog“的应该得到更高的分。同样的,搜索“hound”应该把包含“hound”的排的更靠前面,搜索“pooch”就应该将包含“pooch”的更靠前。所有的3个搜索都返回相同的文档集,但是结果排序不一样。
Solution
我的解决方法是,把同义词扩展从分析器的Tokenizer链移动到QueryParser。不是把查询变成如上面的纵横交错的图,而是把它分为2个部分:主查询和同义词查询。然后我为每个部分独立配置权重,指定每个部分内部为“should occur”。最后将二者使用“must occur”的布尔查询包装起来。
因此,搜索“dog”为被解析为类似这样:
+((dog)^1.2 (hound pooch)^1.1)
1.2和1.1是独立的权重,可以配置。文档必须包含“dog”,”hound”或者“pooch”,但是“dog”更优先显示。
这样来处理同义词,带来了另一个有趣的副作用:它消除了短语查询不支持的问题。如果是“breast cancer”(带引号),将会被解析为这样:
+(("breast cancer")^1.2 (("breast neoplasm") ("breast tumor") ("cancer ? breast") ("cancer ? ? breast"))^1.1)
(问号?的出现是由于停用词“of”和“the”)
这意味着查询带引号的“breast cancer”会匹配所有包含“breast neoplasm,” “breast tumor,” “cancer of the breast,” and “cancer of breast.“字符的文档。
我比原始的SynonymFilterFactory更进一步,针对一个特定的查询构建了所有可能的同义词组合查询。比如查询”dog bite“,同义词文件是:
dog,hound,pooch
bite,nibble
… then the query will be expanded into:
查询将会被扩展为:
dog bite
hound bite
pooch bite
dog nibble
hound nibble
pooch nibble