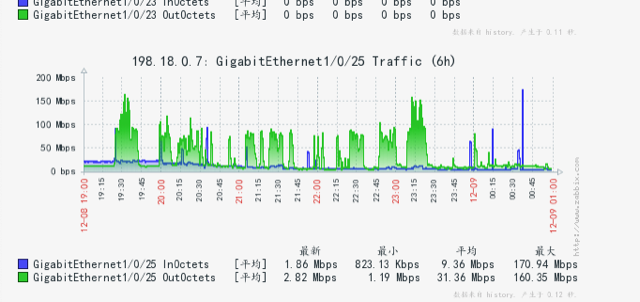
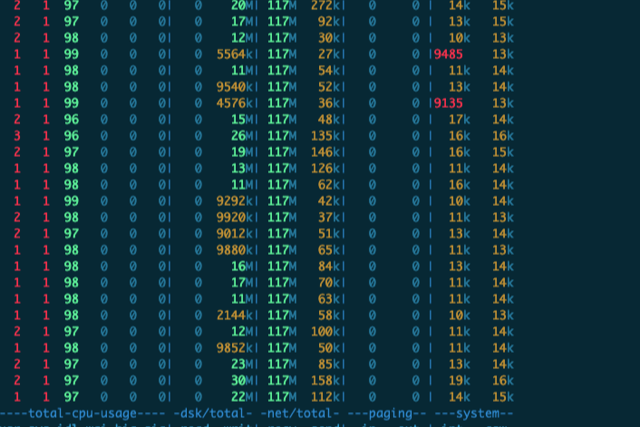
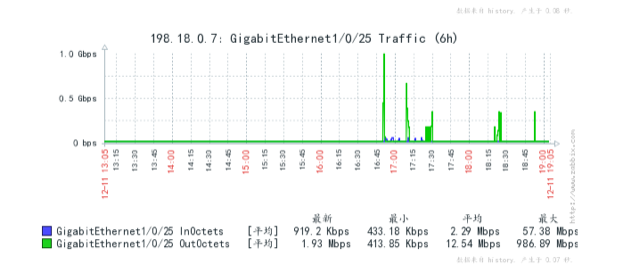
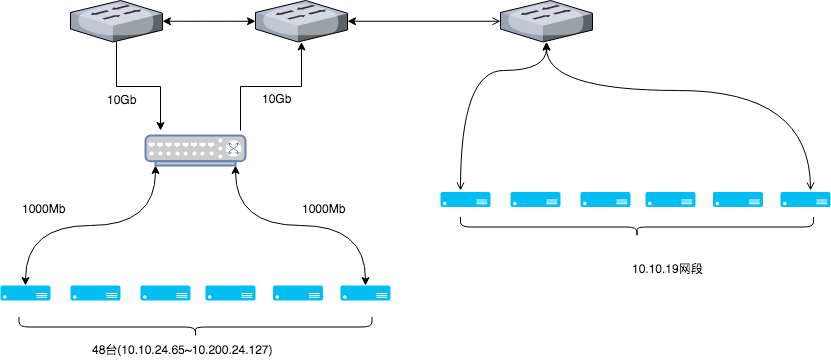
[2018-12-08T19:25:29,993][WARN ][o.e.x.s.t.n.SecurityNetty4Transport] [es35-search.mars.ljnode.com] write and flush on the network layer failed (channel: [id: 0x0e6ac038, L:0.0.0.0/0.0.0.0:8309 ! R:/10.200.24.96:46802]) java.nio.channels.ClosedChannelException: null at io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source) ~[?:?] [2018-12-08T19:25:29,994][WARN ][o.e.x.s.t.n.SecurityNetty4Transport] [es35-search.mars.ljnode.com] write and flush on the network layer failed (channel: [id: 0x0e6ac038, L:0.0.0.0/0.0.0.0:8309 ! R:/10.200.24.96:46802]) java.nio.channels.ClosedChannelException: null at io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source) ~[?:?] [2018-12-08T19:25:31,111][DEBUG][o.e.a.a.c.n.i.TransportNodesInfoAction] [es35-search.mars.ljnode.com] failed to execute on node [_TS9PjOLRke8j12-d59iGA] org.elasticsearch.transport.ReceiveTimeoutTransportException: [es39-search.mars.ljnode.com_node0][10.200.24.86:8309][cluster:monitor/nodes/info[n]] request_id [203863696] timed out after [5000ms] at org.elasticsearch.transport.TransportService$TimeoutHandler.run(TransportService.java:961) [elasticsearch-5.6.9.jar:5.6.9] at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:575) [elasticsearch-5.6.9.jar:5.6.9] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_172] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_172] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_172] [2018-12-08T19:25:32,305][DEBUG][o.e.a.a.c.n.i.TransportNodesInfoAction] [es35-search.mars.ljnode.com] failed to execute on node [yt3RGpgJStKwtOENBe5Trw] org.elasticsearch.transport.ReceiveTimeoutTransportException: [es38-search.mars.ljnode.com_node0][10.200.24.97:8309][cluster:monitor/nodes/info[n]] request_id [203863752] timed out after [5000ms] at org.elasticsearch.transport.TransportService$TimeoutHandler.run(TransportService.java:961) [elasticsearch-5.6.9.jar:5.6.9]