关于Redis序列化及压缩对性能的影响
缘起
公司业务由于广告以及导流的影响,对搜索服务的稳定以及性能提出了更苛刻的要求,为了应对可能的流量突增,特进行了大规模,全方位的性能测试。摸清线上服务的能力,以及定位瓶颈所在。
搜索服务采用了Master-Slave的Redis服务来缓存用户的搜索结果,过期时间在5~10分钟,通过缓存来提升响应时间和并发。key是用户的请求实体json字符串,value自然是搜索结果json串,并没有使用set,hash等类型。
Redis瓶颈
经过一轮的性能测试,最终的瓶颈点落在了Redis上,如下图Grafana监控所示:
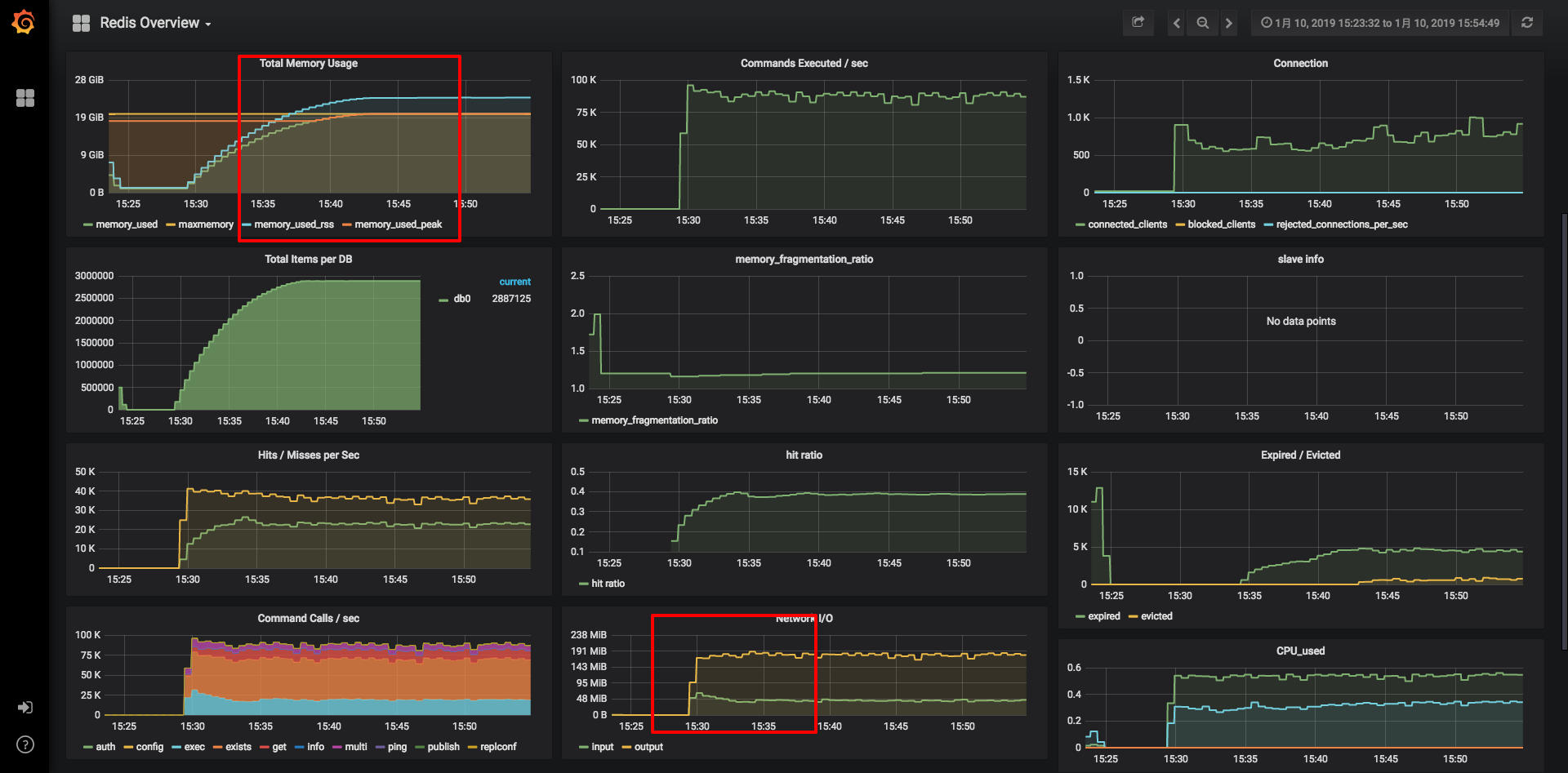
在请求和并发上去之后,redis item迅速增长到300W左右,每秒command数达到近10W。由于redis存储做了限制20G,图中可以看到内存已经满了,item肯定会被频繁置换出去,总数提升不上去。从network上看,output已经达到了近200MB/s,远超运维的限制的100MB/s(千兆网卡极限约100MB,万兆约1000MB)。
核心瓶颈点:
- 存储
- 网络IO