Lucene索引过程&索引文件格式详解
最近2年,整个开源搜索引擎领域,发展迅速,版本迭代很快。 Lucene最近两年从4.0版本已经发布到最新的7.5.0版本,Solr和Elasticsearch也不断跟进升级。Lucene作为核心包,互联网上或者是书籍上关于它的介绍和分析都比较陈旧了,很多都是基于Lucene3.x来。是时候,从底层来分析下最新的Lucene发展情况了。
本文,依Lucene 7.5.0(当时最新)版本描述。
Lucene索引文件的表现
Lucene索引在硬盘上的表现就是一系列的文件,后缀名不同,下面是一个样例:
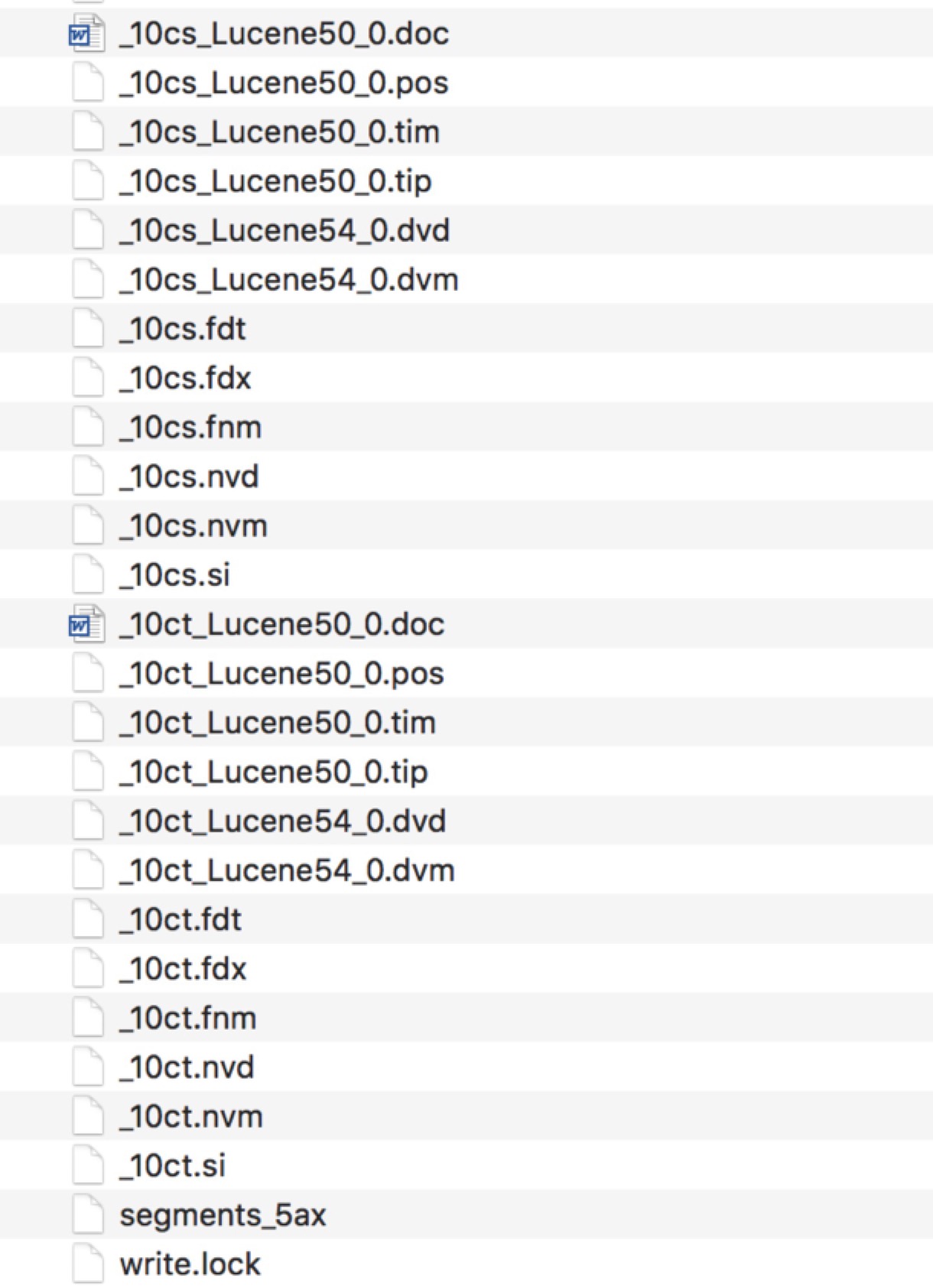
通常,看到这些文件,我们就想打开看看,发现根本无法直接查看。这里存的到底是什么,都有什么作用。很多时候是一脸的懵。为了更好的理解这些文件,下面将一步步进行细致的分析。
Lucene构建索引过程
Lucene源码读起来是比较晦涩的,毕竟它写于20年前,而且作者也是一个具备很多工作经验的老手,读源码是需要一定的时间的。
做索引的入口是IndexWriter.addDocument*(), 当新索引N个Document的时候,是如何生成一系列的索引文件呢。
下面是一个源码导读图:
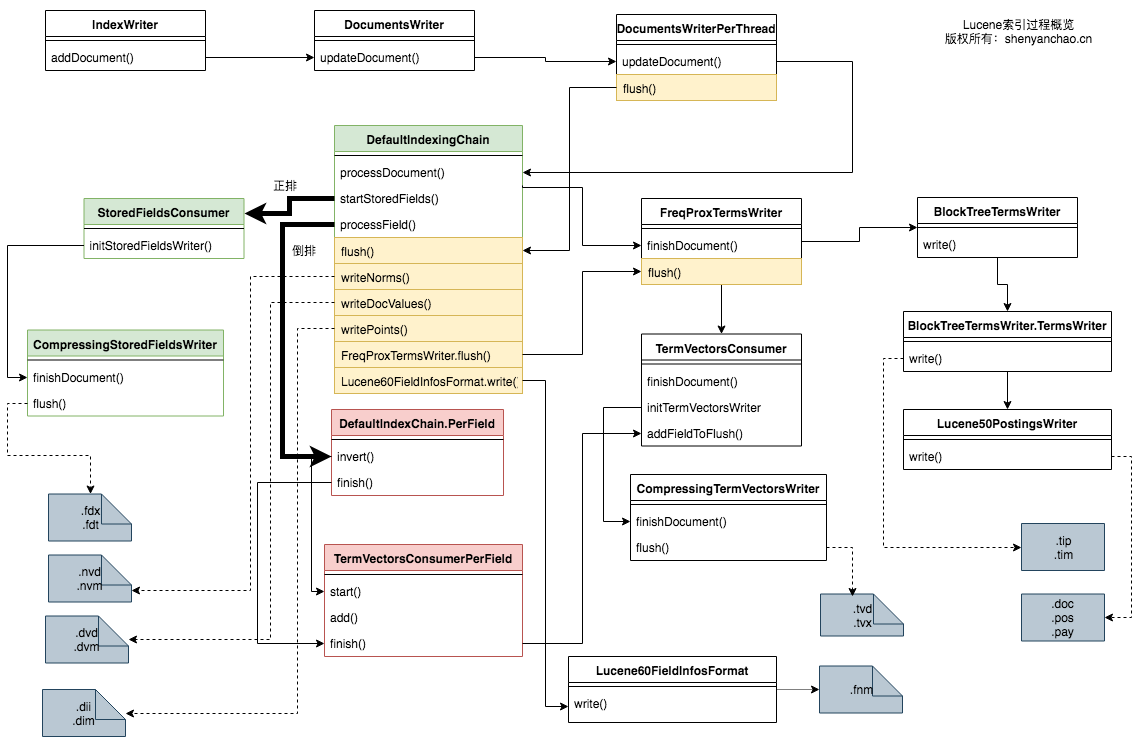
以上重点关注DefaultIndexingChain这个类,processDocument()方法主要是用来构建正排信息。而针对每个Field的processField()则通过一系列的操作,构建出了倒排信息。
什么时候写入磁盘文件中呢?触发点是DocumentsWriterPerThread(DWPT)的flush()方法。触发时间可能是以下条件:
- 超过MaxBufferedDocs限制
- 超过RAMBufferSizeMB限制
- 人为flush()或commit()
- MergePolicy触发
经过以上的处理,就生成了一个最小的独立索引单元,称之为Segment。一个逻辑上的索引(表现为一个目录),是由N多个Segment构成的。
Lucene索引文件
以下描述在Lucene JavaDoc里有详细的介绍,为方便理解,介绍如下:
| 名称 | 扩展名 | 简要描述 | 相关源码 |
|---|---|---|---|
| Segment File | segments_N | commit点信息,其中N是一个36进制表示的值 | SegmentInfos |
| Lock File | write.lock | 文件锁,避免多个writer同时写;默认和索引文件一个目录。 | |
| Segment Info | .si | segment的元数据信息,指明这个segment都包含哪些文件 | Lucene70SegmentInfoFormat |
| Compound File | .cfs, .cfe | 如果启用compound功能,会压缩索引到2个文件内 | Lucene50CompoundFormat |
| Fields | .fnm | 存储有哪些Field,以及相关信息 | Lucene60FieldInfosFormat |
| Field Index | .fdx | Field数据文件的索引 | Lucene50StoredFieldsFormat |
| Field Data | .fdt | Field数据文件 | Lucene50StoredFieldsFormat |
| Term Dictionary | .tim | Term词典 | BlockTreeTermsWriter |
| Term Index | .tip | 指向Term词典的索引 | BlockTreeTermsWriter |
| Frequencies | .doc | 保留包含每个Term的文档列表 | Lucene50PostingsWriter |
| Positions | .pos | Term在文章中出现的位置信息 | Lucene50PostingsWriter |
| Payloads | .pay | offset偏移/payload附加信息 | Lucene50PostingsWriter |
| Norms | .nvd, .nvm | .nvm保存加权因子元数据;.nvd存储加权数据 | Lucene70NormsFormat |
| Per-Document Values | .dvd, .dvm | .dvm存文档正排元数据;.dvd存文档正排数据 | Lucene70DocValuesFormat |
| Term Vector Index | .tvx | 指向tvd的offset | Lucene50TermVectorsFormat |
| Term Vector Data | .tvd | 存储term vector信息 | Lucene50TermVectorsFormat |
| Live Documents | .liv | 活着的文档列表。位图形式 | Lucene50LiveDocsFormat |
| Point Values | .dii, .dim | 多维数据,地理位置等信息,用于处理数值型的查询 | Lucene60PointsFormat |
Segment_N
格式:
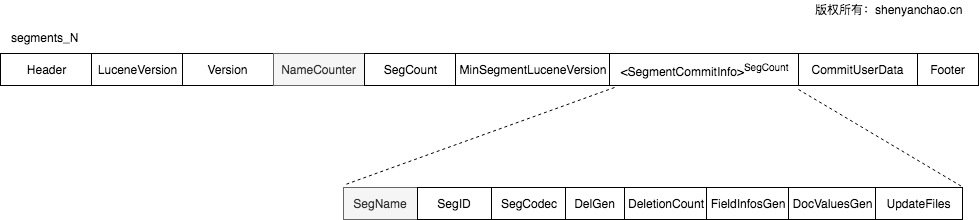
其中N作为后缀,是36进制的数字, 实现方式为:Long.toString(gen, Character.MAX_RADIX)。
segments_N里通过SegName记录了这索引里所有.si文件名。
segment格式(.si)
格式:
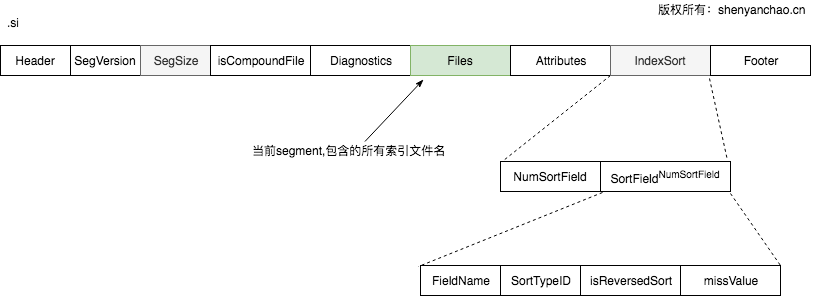
由于一个segment文件,就是一个独立的子索引,其中Files是一个列表,里面存储了本segment所有相关的索引文件。类似长这样:
_8qh.dii
_8qh.dim
_8qh.fdt
_8qh.fdx
_8qh.fnm
_8qh_Lucene50_0.doc
_8qh_Lucene50_0.pos
_8qh_Lucene50_0.tim
_8qh_Lucene50_0.tip
_8qh_Lucene70_0.dvd
_8qh_Lucene70_0.dvm
_8qh.si
IndexSort作为新加入的一个特性,也直接体现在了.si文件里。IndexSort可以加速排序,极大提升性能。
Field info格式(.fnm)
格式:
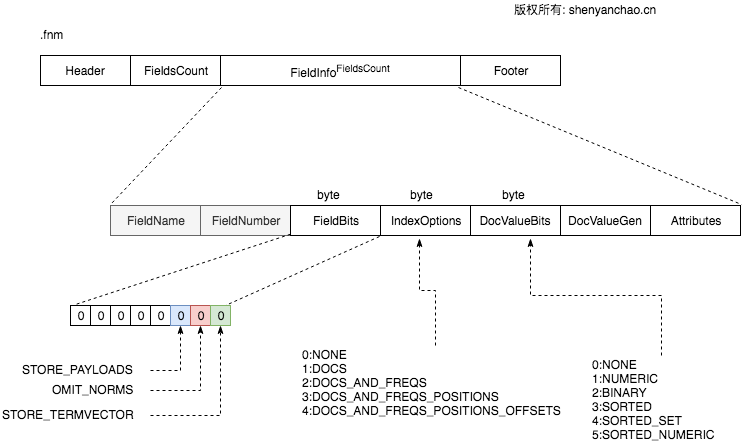
存储了Document所包含的FieldName以及Field的内部表示FieldNumber(可以理解为ID)。 同时,每个Field相关索引配置,都通过byte来存储保存下来。
其中DocValueBits里,不同类型的Field, 处理DocValue数据是不一样的,此处暂时按下不表。后续产出
Field Data格式(.fdx, .fdt)
格式如下所示:
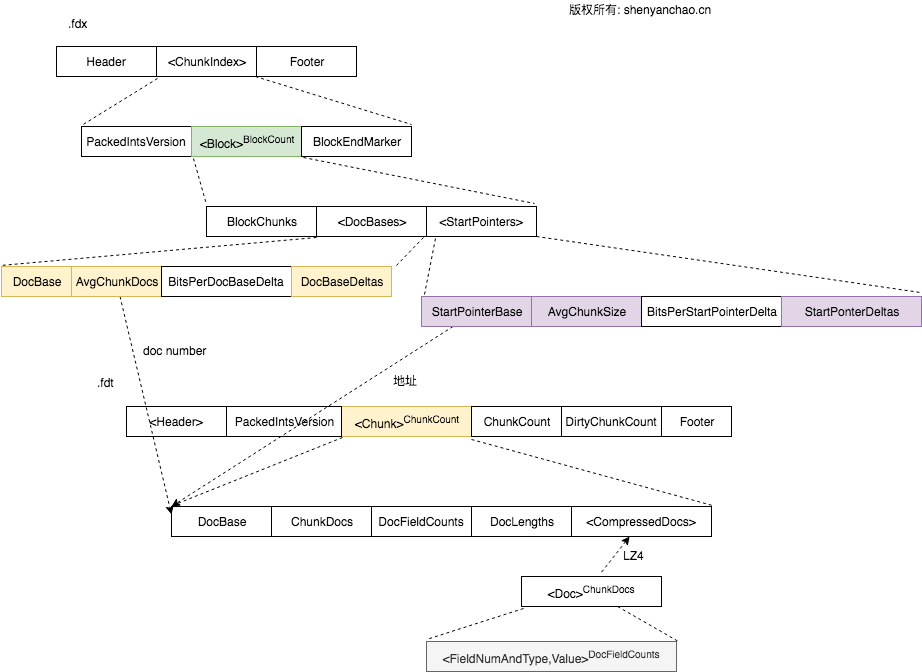
由于fdt正排信息很多,在存到磁盘的时候,使用LZ4算法进行了压缩。每个Chunk大小16KB(1<<14), Doc个数不能超过128个。在fdx中每个Block有1024个Chunk。
CompressDocs是压缩后进行存储的,为了方便理解,可以认为就是一系列的Doc构成的。每个Doc又包含FieldNumAndType和实际的Field Value。
其中FieldNumAndType是一个VLong: 低3位表示Field Type, 其余高位用来表示FieldNumber. 可见Lucene为了最大程度的节省空间,做了很多的Trick.
Term Index格式(.tip,.tim)
格式如下:
.tip:
Header, FSTIndex< IndexStartFP>…, DirOffset, Footer
.tim
Header, PostingsHeader, NodeBlock(…), FieldSummary, DirOffset, Footer
图例如下:
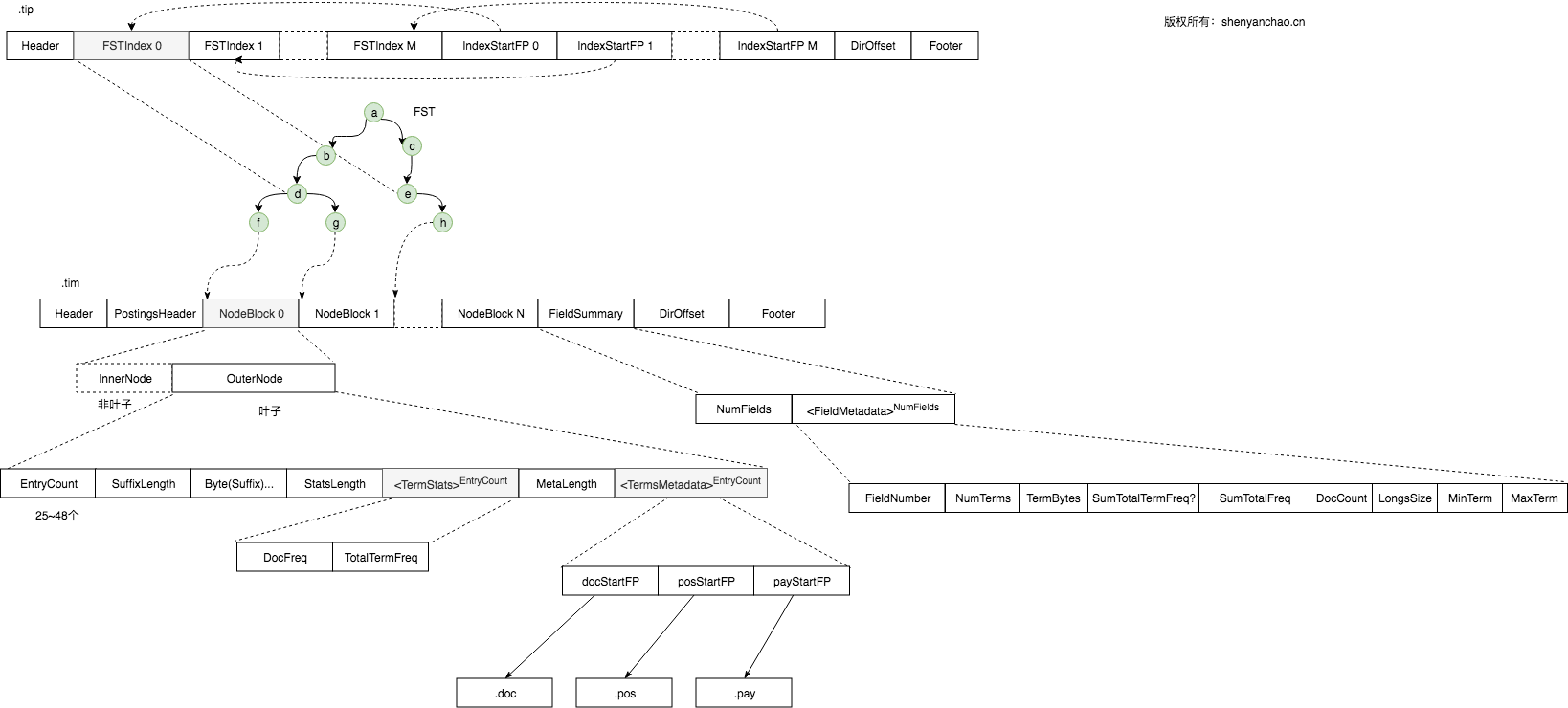
其中FST部分,是直接加载到内存的,详见另外一篇博文,这里为方便理解,直接写画为类TRIE一样。
Pos列表(.doc, .pos, .pay)
doc格式如下:
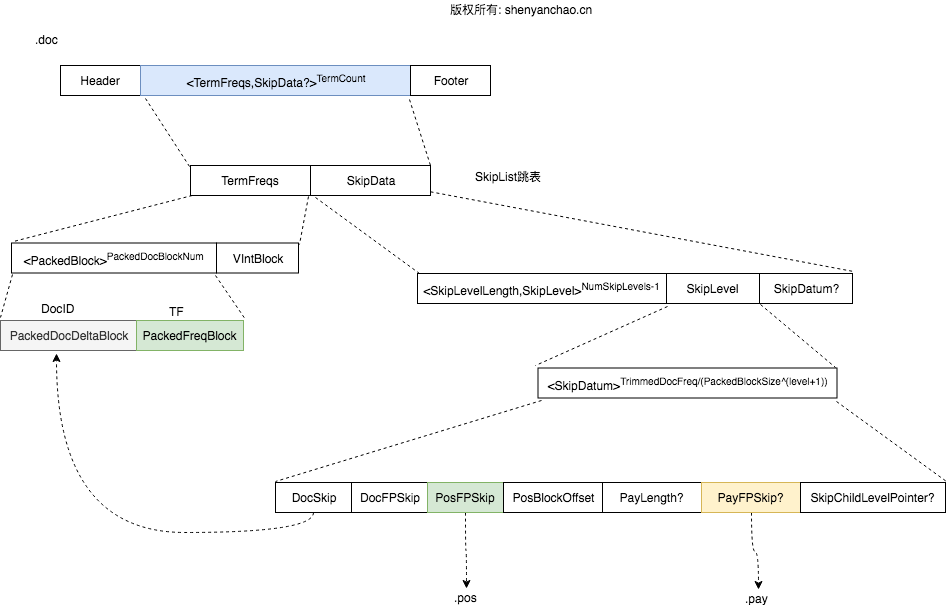
需要注意的是,PackedBlock是对倒排列表的压缩,每128个作为一个Block,不能凑整的情况下,再按VIntBlock进行存储。无论如何存储,Block内部是存储了DocID(PackedDocDeltaBlock)和Term Freq(PackedFreqBlock)的对应关系的。
而Postings则是以SKIPLIST(跳表)进行存储的,这种存储格式保证了快速的查找和归并操作。最底层的SkipDatum通过DocSkip保有对实际doc的指针。PosFPSkip则指向.pos文件,PayFPSkip指向了.pay文件。
pos文件格式:
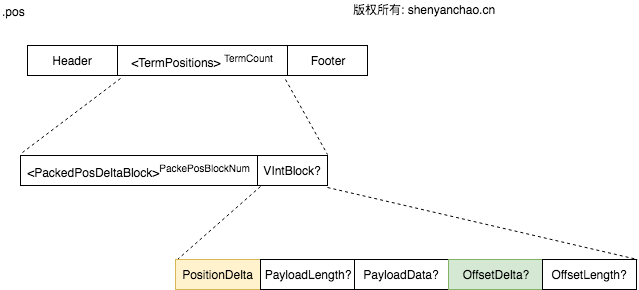
这里的PackedPosDeltaBlock与doc文件的很像,也是进行了压缩成block进行存储。最终通过PostionDelta和OffsetDelta来获取相关的位置和偏移信息。
pay格式:
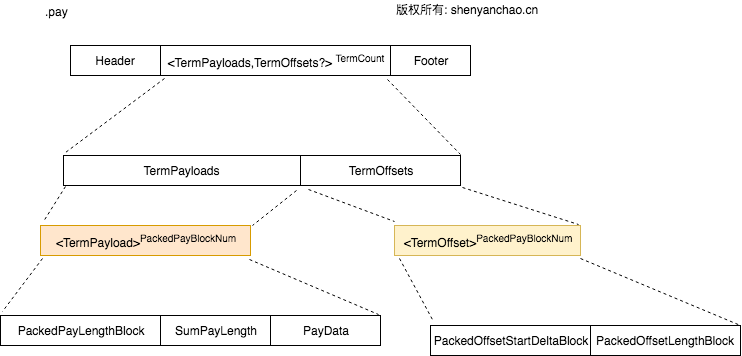
同样做了Block处理,这个文件通过TermPayloads保留了Term和Payload的对应关系;通过TermOffsets保存了Term和Offset的对应关系。
LIV文件格式(.liv)
格式如下:
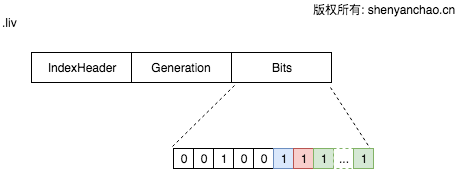
通过FixBitSet位图,来表示哪些是存活的,哪些是被删除的。FixBitSet的底层是通过long[]来模拟实现这样一个大的位图的。
Lucene的4.0版本之前是通过.del文件来标记哪些DocID是被删除的,而现在则改为.liv标记哪些是存活的。个人而言,没有看出来具体原因,毕竟功能实现其实是一样的。
TermVector(.tvx, .tvd)
格式如下:
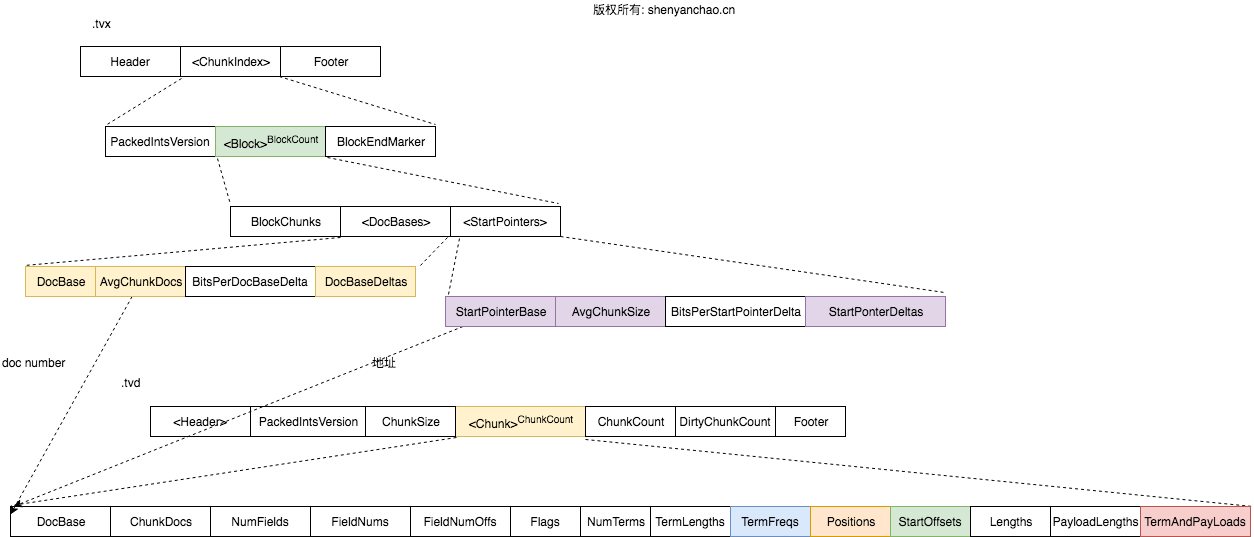
这个格式和Field Data的很相似。区别在于最底层的Chunk直接保留了相关的信息TermFreqs、Positions、StartOffsets、TermAndPayLoads等信息。
从这里也可以看出Term Vector保存的信息很多都是和之前重复的,如果没有必要,完全可以关闭Term Vector功能,避免额外的性能损耗。
Norms (.nvm, .nvd)
格式如下:
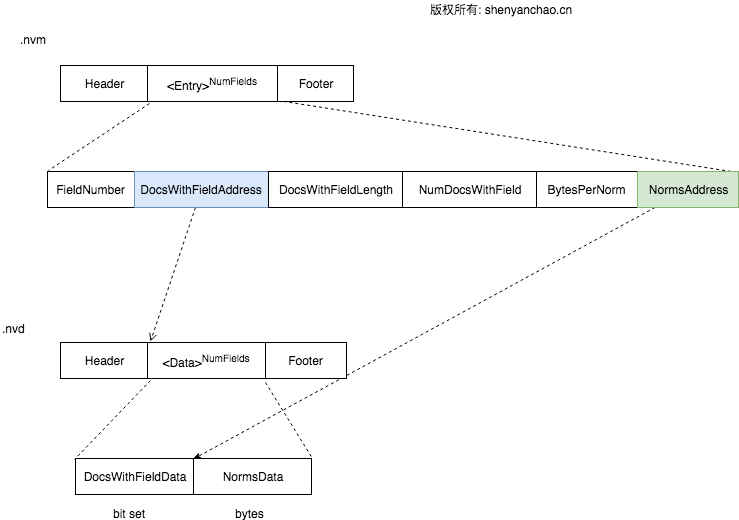
Norms信息通常是用来存储Field\Document的Boost加权信息,然后Lucene7之后,去除了Index时的boost加权操作。因此,目前Norms里存储的东西极少,有逐步被取消的的可能性。
Doc Values(.dvx, .dvd)
DocValues部分,比较复杂,以至于官方文档都没有给出详细的索引格式。以后将作为一个独立的文章还具体解释。
Point Values(.dii,.dim)
Lucene7之后,彻底去除了之前关于数字类型索引和查找的逻辑。之前的TrieInt, TrieLong等完全被删除。取而代之的是IntPoint,LongPoint等类型。
这些类型都是由BKD-Tree来实现的,Point Value被用来实现N-Dimension多维数据的索引和快速的查询,有统一数字型查询、2D位置、3D乃至8D数据查询的趋势,这块将单独作为一个文章进行详细解读。
总结
Lucene索引及其格式,是Solr以及ElasticSearch等分布式搜索引擎的根基。Lucene每一次核心功能的迭代与性能提升都是至关重要的。对Lucene索引过程以及索引文件格式的理解,有助于从更高层面来分析和看待生产环境出现的问题。
参考文档: